
Elastic Compute
Flexible VM and bare-metal capacity sized for AI pipelines, backend services, and burst-heavy workloads.
Explore itGPU-powered compute, cross-region performance, and hands-on support in Southeast Asia - built for real production workloads.
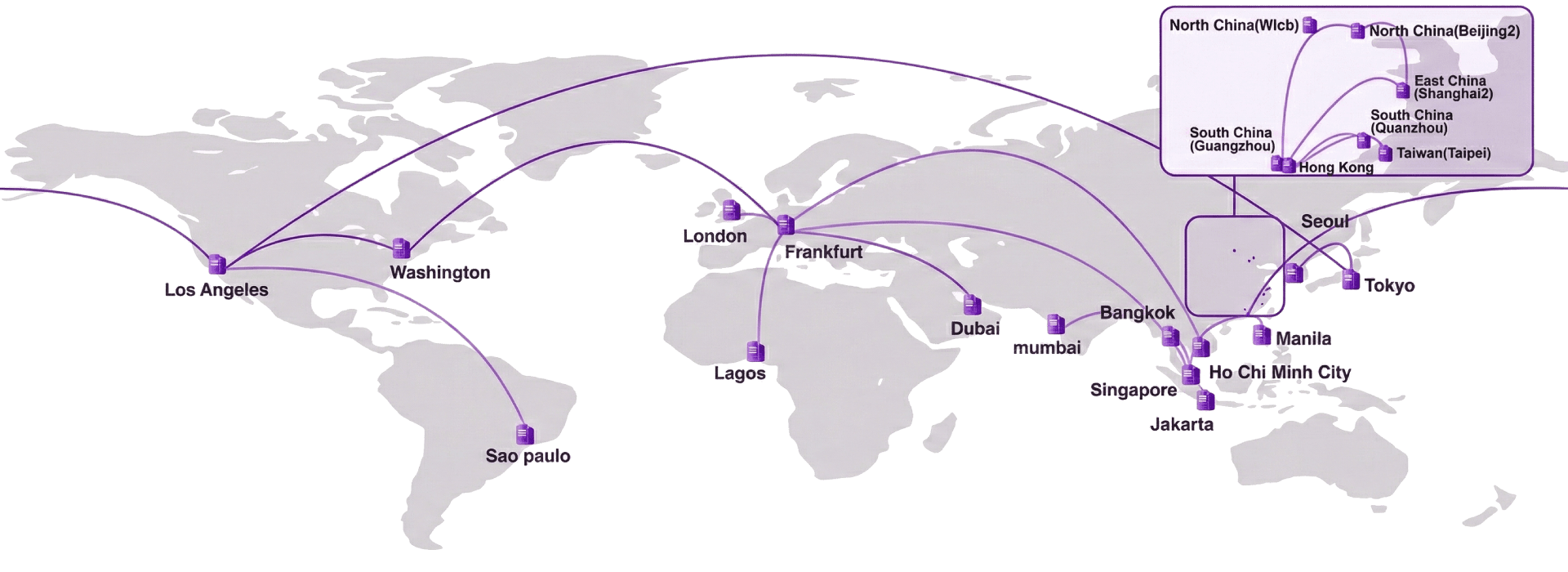
Regional coverage and optimized routing for SEA, China, the US, and Europe.
18+
Regions
54+
Availability Zones
120+
Edge PoPs
Products and Services
Browse the infrastructure layers altuscloud combines for production-ready deployments across compute, networking, data, and operations.
Flexible VM and bare-metal capacity sized for AI pipelines, backend services, and burst-heavy workloads.
Explore itOn-demand and reserved GPU infrastructure for training, fine-tuning, and production inference.
Explore itLow-latency persistent volumes for databases, model checkpoints, and business-critical services.
Explore itDurable storage for datasets, logs, media pipelines, and large-scale AI artifacts.
Explore itCompute instances tuned for modern orchestration stacks and service deployment workflows.
Explore itStronger infrastructure positioning for teams that need AI-first cloud operations.
GPU-ready cloud infrastructure without the usual waitlist or generic-hosting compromises.
Optimized routing between SEA, China, the US, and Europe for lower-latency regional traffic.
Pay-as-you-go, reserved, and dedicated models with practical FinOps guidance built in.
Local engineers in SEA timezones with fast escalation paths and architecture guidance.
Problem-to-solution framing for the workloads that actually convert.
Problem: Train and deploy models without stitching together fragmented cloud layers.
Solution: Run model pipelines, inference APIs, and agents on one regional footprint.
Problem: Multi-region apps need dependable compute, storage, and network control.
Solution: Deploy scalable service stacks with private networking and stable performance.
Problem: Streaming, ETL, and analytics pipelines outgrow generic infrastructure patterns.
Solution: Combine managed data services with GPU or VM capacity tuned for throughput.
Problem: Realtime traffic punishes weak routing and slow support loops.
Solution: Place infrastructure closer to users with low-latency network design.
Talk to our solution architects and get a tailored design within 24 hours.